|
|
 |
|
|
|
Adaptive moments | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Adaptive moments are the second moments of the object intensity, measured using a particular scheme designed to have near-optimal signal-to-noise ratio. Moments are measured using a radial weight function interactively adapted to the shape (ellipticity) and size of the object. This elliptical weight function has a signal-to-noise advantage over axially symmetric weight functions. In principle there is an optimal (in terms of signal-to-noise) radial shape for the weight function, which is related to the light profile of the object itself. In practice a Gaussian with size matched to that of the object is used, and is nearly optimal. Details can be found in Bernstein & Jarvis (2002). The outputs included in the SDSS data release are the following:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The asinh magnitude | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Magnitudes within the SDSS are expressed as inverse hyperbolic sine
(or "asinh") magnitudes, described in detail by Lupton, Gunn, & Szalay (1999). They are sometimes
referred to informally as luptitudes . The transformation
from linear flux measurements to asinh magnitudes is designed to be
virtually identical to the standard astronomical magnitude at high
signal-to-noise ratio, but to behave reasonably at low signal-to-noise
ratio and even at negative values of flux, where the logarithm in the
Pogson magnitude m=-(2.5/ln10)*[asinh((f/f0)/2b)+ln(b)]. Here, f0 is given by the classical zero point of the magnitude scale, i.e., f0 is the flux of an object with conventional magnitude of zero. The quantity b is measured relative to f0, and thus is dimensionless; it is given in the table of asinh softening parameters (Table 21 in the EDR paper), along with the asinh magnitude associated with a zero flux object. The table also lists the flux corresponding to 10f0, above which the asinh magnitude and the traditional logarithmic magnitude differ by less than 1% in flux. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Astrometry | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
A detailed description of the astrometric calibration is given in Pier et al. (2003) (AJ, or astro-ph/0211375). Portions of that discussion are summarized here, and on the astrometry quality overview page. The r photometric CCDs serve as the astrometric reference CCDs for the SDSS. That is, the positions for SDSS objects are based on the r centroids and calibrations. The r CCDs are calibrated by matching up bright stars detected by SDSS with existing astrometric reference catalogs. One of two reduction strategies is employed, depending on the coverage of the astrometric catalogs:
The r CCDs are therefore calibrated directly against the primary astrometric
reference catalog. Frames Each drift scan is processed separately. All six camera columns are processed in a single reduction. In brief, stars detected on the r CCDs if calibrating against UCAC, or stars detected on the astrometric CCDs transformed to r coordinates if calibrating against Tycho-2, are matched to catalog stars. Transformations from r pixel coordinates to catalog mean place (CMP) celestial coordinates are derived using a running-means least-squares fit to a focal plane model, using all six r CCDs together to solve for both the telescope tracking and the r CCDs' focal plane offsets, rotations, and scales, combined with smoothing spline fits to the intermediate residuals. These transformations, comprising the calibrations for the r CCDs, are then applied to the stars detected on the r CCDs, converting them to CMP coordinates and creating a catalog of secondary astrometric standards. Stars detected on the u, g, i, and z CCDs are then matched to this secondary catalog, and a similar fitting procedure (each CCD is fitted separately) is used to derive transformations from the pixel coordinates for the other photometric CCDs to CMP celestial coordinates, comprising the calibrations for the u, g, i, and z CCDs. Note: At the edges of pixels, the quantities objc_rowc and objc_colc take integer values. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Image Classification | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
This page provides detailed descriptions of various morphological
outputs of the photometry pipelines. We also provide discussion of
some methodology; for details of the Photo pipeline processing please
visit the Photo pipeline
page. Other photometric outputs, specifically the various
magnitudes, are described on the photometry
page . .
The frames pipeline
Star/Galaxy Classification
In particular, Lupton et al. (2001a) show that the following simple cut
works at the 95% confidence level for our data to r=21
and even somewhat fainter:
psfMag - (dev_L>exp_L)?deVMag:expMag)>0.145
If satisfied, type
is set to GALAXY
for that band; otherwise, type
is set to STAR
. The global type objc_type
is set according to the same criterion, applied to the
summed fluxes from all bands in which the object is detected.
Experimentation has shown that simple variants on this scheme, such
as defining galaxies as those objects classified as such in any two of
the three high signal-to-noise ratio bands (namely, g, r,
and i), work better in some
circumstances. This scheme occasionally fails to distinguish pairs of
stars with separation small enough (<2") that the deblender does
not split them; it also occasionally classifies Seyfert galaxies with
particularly bright nuclei as stars.
Further information to refine the star-galaxy separation further may
be used, depending on scientific application. For example,
Scranton et al. (2001) advocate applying a Bayesian prior to the above
difference between the PSF and exponential magnitudes, depending on
seeing and using prior knowledge about the counts of galaxies and
stars with magnitude.
Radial Profiles
When converting the profMean values to a local surface
brightness, it is not the best approach to assign the mean
surface brightness to some radius within the annulus and then linearly
interpolate between radial bins. Do not use smoothing
splines, as they will not go through the points in the cumulative
profile and thus (obviously) will not conserve flux. What frames
does, e.g., in determining the Petrosian ratio, is to fit a taut spline to the
cumulative profile and then differentiate that spline fit,
after transforming both the radii and cumulative profiles with asinh
functions. We recommend doing the same here.
Surface Brightness & Concentration Index
It turns out that the ratio of petroR50 to petroR90, the
so-called "inverse concentration index", is correlated with
morphology (Shimasaku et al. 2001, Strateva et al. 2001). Galaxies with a de
Vaucouleurs profile have an inverse concentration index of around 0.3;
exponential galaxies have an inverse concentration index of around
0.43. Thus, this parameter can be used as a simple morphological
classifier.
An important caveat when using these quantities is that they
are not corrected for seeing. This causes the surface
brightness to be underestimated, and the inverse concentration index
to be overestimated, for objects of size comparable to the PSF. The
amplitudes of these effects, however, are not yet well characterized.
Model Fit Likelihoods and Parameters
f(deV_L)=deV_L/[deV_L+exp_L+star_L]
and similarly for f(exp_L) and f(star_L). A fractional likelihood greater than 0.5 for any of these three profiles is generally a good threshold for object classification. This works well in the range 18<r<21.5; at the bright end, the likelihoods have a tendency to underflow to zero, which makes them less useful. In particular, star_L is often zero for bright stars. For future data releases we will incorporate improvements to the model fits to give more meaningful results at the bright end.
Ellipticities
The first method measures flux-weighted second moments,
defined as:
Isophotal Quantities
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Deblending Overlapping Objects | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
One of the jobs of the frames pipeline
Bright objects are measured at least twice: once with a global sky
Once objects are detected, they are deblended by identifying individual peaks within each object, merging the list of peaks across bands, and adaptively determining the profile of images associated with each peak, which sum to form the original image in each band. The originally detected object is
referred to as the "parent" object and has the flag The list of peaks in the parent is trimmed to combine peaks (from different bands) that are too close to each other (if this happens, the flag PEAKS_TOO_CLOSE is set in the parent). If there are more than 25 peaks, only the most significant are kept, and the flag DEBLEND_TOO_MANY_PEAKS is set in the parent.
In a number of situations, the deblender decides not to process a BLENDED object; in this case
the object is flagged as NODEBLEND. Most objects with EDGE set are not deblended. The exceptions
are when the object is large enough (larger than roughly an arcminute) that it will most likely not be
completely included in the adjacent scan line either; in this case, DEBLENDED_AT_EDGE is set, and
the deblender gives it its best shot. When an object is larger than half a frame,the deblender also
gives up, and the object is flagged as TOO_LARGE. Other intricacies of the deblending results are
recorded in flags described on the Object Flags section of the Flags page On average, about 15% - 20% of all detected objects are blended, and many of these are superpositions of galaxies that the deblender successfully treats by separating the images of the nearby objects. Thus, it is almost always the childless (nChild=0, or !BLENDED || (BLENDED && NODEBLEND)) objects that are of most interest for science applications. Occasionally, very large galaxies may be treated somewhat improperly, but this is quite rare. The behavior of the deblender of overlapping images has been further improved since the DR1; these changes are most important for bright galaxies of large angular extent (> 1 arcmin). In the EDR, and to a lesser extent in the DR1, bright galaxies were occasionally "shredded" by the deblender, i.e., interpreted as two or more objects and taken apart. With improvements in the code that finds the center of large galaxies in the presence of superposed stars, and the deblending of stars superposed on galaxies, this shredding now rarely happens. Indeed, inspections of several hundred NGC galaxies shows that the deblend is correct in 95% of the cases; most of the exceptions are irregular galaxies of various sorts. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The fiber magnitude | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The flux contained within the aperture of a spectroscopic fiber
Notes: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The model magnitude | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Important Note for EDR and DR1 data ONLY:Comparing the model (i.e., exponential and de Vaucouleurs fits) and Petrosian magnitudes of bright galaxies in EDR and DR1 data shows a systematic offset of about 0.2 magnitudes (in the sense that the model magnitudes are brighter). This turns out to be due to a bug in the way the PSF was convolved with the models (this bug affected the model magnitudes even when they were fit only to the central 4.4" radius of each object). This caused problems for very small objects (i.e., close to being unresolved). The code forces model and PSF magnitudes of unresolved objects to be the same in the mean by application of an aperture correction, which then gets applied to all objects. The net result is that the model magnitudes are fine for unresolved objects, but systematically offset for galaxies brighter than at least 20th mag. Therefore, model magnitudes should NOT be used in EDR and DR1 data. This problem has been corrected as of DR2.
Just as the PSF magnitudes
1. a pure deVaucouleurs profile:
2. a pure exponential profile Each model has an arbitrary axis ratio and position angle. Although for large objects it is possible and even desirable to fit more complicated models (e.g., bulge plus disk), the computational expense to compute them is not justified for the majority of the detected objects. The models are convolved with a double-Gaussian fit to the PSF, which is provided by psp. Residuals between the double-Gaussian and the full KL PSF model are added on for just the central PSF component of the image.
These fitting procedures yield the quantities
Note that these quantities correctly model the effects of the PSF. Errors for each of the last two quantities (which are based only on photon statistics) are also reported. We apply aperture corrections to make these model magnitudes equal the PSF magnitudes in the case of an unresolved object. In order to measure unbiased colors of galaxies, we measure their flux through equivalent apertures in all bands. We choose the model (exponential or deVaucouleurs) of higher likelihood in the r filter, and apply that model (i.e., allowing only the amplitude to vary) in the other bands after convolving with the appropriate PSF in each band. The resulting magnitudes are termed modelMag. The resulting estimate of galaxy color will be unbiased in the absence of color gradients. Systematic differences from Petrosian colors are in fact often seen due to color gradients, in which case the concept of a global galaxy color is somewhat ambiguous. For faint galaxies, the model colors have appreciably higher signal-to-noise ratio than do the Petrosian colors. Due to the way in which model fits are carried out, there is some weak discretization of model parameters, especially r_exp and r_deV. This is yet to be fixed. Two other issues (negative axis ratios, and bad model mags for bright objects) have been fixed since the EDR.
Caveat: At bright magnitudes (r <~ 18), model magnitudes
may not be a robust means to select objects by flux.
For example, model magnitudes in target | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The Petrosian magnitude | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Stored as petroMag. For galaxy photometry, measuring flux is more difficult than for stars, because galaxies do not all have the same radial surface brightness profile, and have no sharp edges. In order to avoid biases, we wish to measure a constant fraction of the total light, independent of the position and distance of the object. To satisfy these requirements, the SDSS has adopted a modified form of the Petrosian (1976) system, measuring galaxy fluxes within a circular aperture whose radius is defined by the shape of the azimuthally averaged light profile.
We define the "Petrosian ratio" RP at a radius
r from
the center of an object to be the ratio of the local surface
brightness in an annulus at r to the mean surface brightness within
r, as described by Blanton et al. 2001a, Yasuda et al. 2001: where I(r) is the azimuthally averaged surface brightness profile.
The Petrosian radius rP is defined as the radius
at which
RP(rP) equals some specified value
RP,lim, set to 0.2 in our case. The
Petrosian flux in any band is then defined as the flux within a
certain number NP (equal to 2.0 in our case) of
r Petrosian radii: 
In the SDSS five-band photometry, the aperture in all bands is set by
the profile of the galaxy in the r band alone. This procedure
ensures that the color measured by comparing the Petrosian flux
FP in different bands is measured through a
consistent aperture.
The aperture 2rP is large enough to contain nearly all of
the flux for typical galaxy profiles, but small enough that the sky noise in
FP is small. Thus, even substantial errors in
rP cause only
small errors in the Petrosian flux (typical statistical errors near
the spectroscopic flux limit of r ~17.7 are < 5%),
although these errors are correlated.
The Petrosian radius in each band is the parameter petroRad, and
the Petrosian magnitude in each band (calculated, remember, using only
petroRad for the r band) is the parameter petroMag.
In practice, there are a number of complications associated with this
definition, because noise, substructure, and the finite size of
objects can cause objects to have no Petrosian radius, or more than
one. Those with more than one are flagged
How well does the Petrosian magnitude perform as a reliable and
complete measure of galaxy flux? Theoretically, the Petrosian
magnitudes defined here should recover essentially all of the flux of
an exponential galaxy profile and about 80% of the flux for a de
Vaucouleurs profile. As shown by Blanton et al. (2001a), this fraction is
fairly constant with axis ratio, while as galaxies become smaller (due
to worse seeing or greater distance) the fraction of light recovered
becomes closer to that fraction measured for a typical PSF, about 95%
in the case of the SDSS. This implies that the fraction of flux
measured for exponential profiles decreases while the fraction of flux
measured for deVaucouleurs profiles increases as a function of
distance. However, for galaxies in the spectroscopic sample
(r<17.7), these effects are small;
the Petrosian radius measured by frames | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The PSF magnitude | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Stored as psfMag. For isolated stars, which are well-described by the point spread function
(PSF), the optimal
measure of the total flux is determined by fitting a PSF model to the
object. In practice, we do this by sync-shifting the image of a star
so that it is exactly centered on a pixel, and then fitting a Gaussian
model of the PSF to it. This fit is carried out on the local PSF KL
model at each position as well; the difference
between the two is then a local aperture correction, which gives a
corrected PSF magnitude. Finally, we use bright stars to determine a
further aperture correction to a radius of 7.4" as a function of
seeing, and apply this to each frame based on its seeing. This involved
procedure is necessary to take into account the full variation of the
PSF across the field,
including the low signal-to-noise ratio wings. Empirically, this
reduces the seeing-dependence of the photometry to below 0.02 mag for
seeing as poor as 2". The resulting magnitude is stored in the
quantity psfMag. The flag | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Reddening and Extinction Corrections | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Reddening corrections in magnitudes at the position of each object,
extinction, are computed following Schlegel, Finkbeiner & Davis (1998). These
corrections are not applied to the magnitudes ugriz in the
databases. If you want corrected magnitudes, you should use dered_[ugriz]; these are the extinction-corrected model magnitudes | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Image processing flags | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
For objects in the calibrated object lists, the photometric pipeline sets a number of flags that indicate the status of each object, warn of possible problems with the image itself, and warn of possible problems in the measurement of various quantities associated with the object. For yet more details, refer to Robert Lupton's flags document. Possible problems associated with individual pixels in the reduced
images ("corrected frames") are traced in the
Objects in the catalog have two major sets of flags:
The "status" of an objectThe catalogs contain multiple detections of objects from overlapping CCD frames. For most applications, remove duplicate detections of the same objects by considering only those which have the "primary" flag set in the status entry of the PhotoObjAll table and its Views. A description of status is provided on the details page. The details of
determining primary status and of the remaining flags stored in
status are found on the algorithms page describing the
resolution of overlaps (resolve) Object "flags"The photometric pipeline's flags describe how certain measurements were performed for each object, and which measurements are considered unreliable or have failed altogether. You must interpret the flags correctly to obtain meaningful results. For each object, there are 59 flags stored as bit fields in a single 64-bit table column called flags in the PhotoObjAll table (and its Views). There are two versions of the flag variable for each object:
Note: This differs from the tsObj files Here we describe which flags should be checked for which measurements, including whether you need to look at the flag in each filter, or at the general flags. RecommendationsClean sample of point sourcesIn a given band, first select objects with PRIMARY status and apply the SDSS star-galaxy separation. Then, define the following meta-flags: DEBLEND_PROBLEMS = PEAKCENTER || NOTCHECKED || (DEBLEND_NOPEAK && psfErr>0.2)INTERP_PROBLEMS = PSF_FLUX_INTERP || BAD_COUNTS_ERROR || (INTERP_CENTER && CR) Then include only objects that satisfy the following in the band in question: BINNED1 && !BRIGHT && !SATURATED && !EDGE && (!BLENDED || NODEBLEND) && !NOPROFILE && !INTERP_PROBLEMS && !DEBLEND_PROBLEMS If you are very picky, you probably will want not to include the NODEBLEND objects. Note that selecting PRIMARY objects implies !BRIGHT && (!BLENDED || NODEBLEND || nchild == 0) These are used in the SDSS quasar target selection code Clean sample of galaxiesAs for point sources, but don't cut on EDGE (large galaxies often run into the edge). Also, you may not need to worry about the INTERP problems. The BRIGHTEST_GALAXY_CHILD may be useful if you are looking at bright galaxies; it needs further testing. If you want to select (or reject against) moving objects (asteroids), cut on the DEBLENDED_AS_MOVING flag, and then cut on the motion itself. See the the SDSS Moving Objects Catalog for more details. An interesting experiment is to remove the restriction on the DEBLENDED_AS_MOVING flag to find objects with very small proper motion (i.e., those beyond Saturn). Descriptions of all flagsFlags that affect the object's statusThese flags must be considered to reject duplicate catalog entries of the same object. By using only objects with PRIMARY status (see above), you automatically account for the most common cases: those objects which are BRIGHT, or which have been deblended (decomposed) into one or more child objects which are listed individually. In the tables, Flag names link to detailed descriptions. The "In Obj Flags?" column indicates that this flag will be set in the general (per object) "flags" column if this flag is set in any of the filters. "Bit" is the number of the bit. To find the hexadecimal values used for testing if a flag is set, please see the PhotoFlags table.
Flags that indicate problems with the raw dataThese flags are mainly informational and important only for some objects and science applications.
Flags that indicate problems with the imageThese flags may be hints that an object may not be real or that a measurement on the object failed.
Problems associated with specific quantitiesSome flags simply indicate that the quantity in question could not be
measured. Others indicate more subtle aspects of the measurements,
particularly for Petrosian
quantities
All flags so far indicate some problem or failure of a measurement. The following flags provide information about the processing, but do not indicate a severe problem or failure. Informational flags related to deblending
Further informational flags
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Match and MatchHead Tables | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Computing the Match tableJim Gray, Alex Szalay, Robert Lupton, Jeff Munn, Ani Thakar
The SDSS data can be used for temporal studies of objects that are re-observed at different times. The SDSS survey observes about 10% of the Northern survey area 2 or more times, and observes the Southern stripe more than a dozen times.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mode | Total | nChild=0 |
| primary | 52,525,576 | 52,525,576 |
| secondary | 14,596,931 | 14,596,931 |
| family | 17,074,000 | 6,153,714 |
| outside | 126,819 | 126,819 |
And here are the flag counts for DR1
| Dr1 Count | Flag | Description | 72,926,906 | SET | Object's status has been set in reference to its own run |
| 72,926,906 | GOOD | Object is good as determined by its object flags. Absence implies bad. |
| 10,186,591 | DUPLICATE | Object has one or more duplicate detections in an adjacent field of the same Frames Pipeline Run. |
| 67,029,849 | OK_RUN | Object is usable, it is located within the primary range of rows for this field. |
| 66,894,914 | RESOLVED | Object has been resolved against other runs. |
| 66,839,376 | PSEGMENT | Object Belongs to a PRIMARY segment. This does not imply that this is a primary object. |
| 387,964 | FIRST_FIELD | Object belongs to the first field in its segment. Used to distinguish objects in fields shared by two segments. |
| 62,728,244 | OK_SCANLINE | Object lies within valid nu range for its scanline. |
| 53,60,3453 | OK_STRIPE | Object lies within valid eta range for its stripe. |
Create table Match (objID bigint not null,
matchObjID bigint not null,
distance float not null,
type tinyint not null,
matchType tinyint not null,
Mode tinyint not null,
matchMode tinyint not null,
primary key (objID, matchObjID)
) ON [Neighbors]
-- now populate the table
insert Match
select N.*
from (Neighbors N join PhotoObj P1 on N.objID = P1.objID)
join PhotoObj P2 on N.NeighborObjID = P2.objID
where ((N.objID ^ N.neighborObjID) & 0x0000FFFF00000000) != 0 -- dif runs
and distance < 1.0/60.0 -- within 1 arcsecond of one another
One arcsecond is a large error in Sloan Positioning - the vast majority
(95%) are within 0.5 arcsecond. But a particular cluster may not form a
complete graph (all members connected to all others). To make the graph fully
transitive, we repeatedly execute the query to add the "curved" arcs in the figure below.
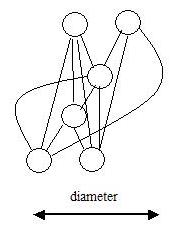
-- compute triples
create table ##Trip(objid bigint, matchObjID bigint, distance float,
type tinyint, neighborType tinyint,
mode tinyInt, matchMode tinyInt,
primary key (objID, matchObjID))
again: truncate table ##trip
-- compute triples
insert ##trip
select distinct a.objID, b.matchObjID, 0,
a.type, b.matchType, a.mode, b.matchMode
from Match a join Match b on a.matchObjID = b.objID
where a.objID != b.matchObjID
and (a.objid & 0x0000FFFF00000000)!=
(b.matchObjID& 0x0000FFFF00000000) -- Different runs
-- now delete the pairs we already have in Match
delete ##trip
where 0 != (
select count(*)
from Match p
where p.objID = ##trip.objID and p.matchObjID = ##trip.matchObjID
)
-- compute the distance between the remaining tripples
select 'adding ' + cast(count(*) as varchar(20)) + ' tripples.'
update ##trip
set distance =
(select min(N.distance)
from ##trip t join Neighbors N
on t.objID = N.objID and t.matchObjID = N.NeighborObjID)
-- now add these into Match and repeat till no more rows.
insert Match select * from ##trip
if @@rowcount > 0 goto again
drop table ##trip
-- build a table of cluster IDs (minimum object ID of each cluster).
Create table MatchHead (
objID bigint not null primary key,
averageRa float not null default 0,
averageDec float not null default 0,
varRa float not null default 0, -- variance in RA
varDec float not null default 0, -- variance in DEC
matchCount tinyInt not null default 0, -- number in cluster
missCount tinyInt not null default 0 -- runs missing from cluster
) ON [Neighbors]
-- compute the minimum object IDs.
Create table ##MinID (objID bigint primary key)
Insert ##MinID
select distinct objID
from Match MinId
where 0 = ( select count(*)
from Match m
where MinId.objID = m.objID
and MinId.objID > m.matchObjID)
-- compute all pairs of objIDs in a cluster (including x,x for the headID)
create table ##pairs (objID bigint not null,
matchObjID bigint not null
primary key(objID, matchObjID))
insert ##pairs
select h.objID, m.matchObjID
from ##MinID h join Match m on h.objID = m.objID
insert ##pairs select objID, objID from ##MinID
-- now populate the MatchHead table with minObjID and statistics
Insert MatchHead
Select MinID.objID, avg(ra), avg(dec),
coalesce(stdev(ra),0), coalesce(stdev(dec),0),
count(m.objid & 0x0000FFFF00000000), -- count runs
0 -- count misses later
from ##MinID as MinID,
##pairs as m,
PhotoObj as o
where MinID.objID = m.objID
and m.matchObjID = o.objID
group by MinID.objID
order by MinID.objID
-- cleanup
Drop table ##MinID
Drop table ##pairs
The number missing from the cluster is computed in the next section.
We will create a table of "dropouts", places where a match cluster should have an object but does not.
Create table MatchMiss (objID bigint not null, --- the unique ID of the cluster Run int not null, -- the run that is missing a member of this cluster. Primary key (objID, Run) ) Logic: From Match find all pairs of runs that overlap Form the domain that is the union of the intersection of these pairs. Now build T, a list of all objects primary/secondary type (3,5, 6) objects that are in this domain. Subtract from T all objects that appear in Match Add these objects and the missing run number(s) to MatchMiss For each object in MatchHead, count the number of overlaps it is a member of. (MatchHead, runs) If this is equals the number of runs the match list then
| Match | 12,294,016 |
| add from triples | 19,040 |
| add from triples | 322 |
| add from triples | 16 |
| add from triples | 2 |
| add from triples | 0 |
| MinID | 5,545,446 |
| Mirror Pairs | 5,849,459 |
| Paris from match | 5,545,446 |
| MatchHead | 5,545,446 |
The objective of the photometric calibration process is to tie the SDSS imaging data to an AB magnitude system, and specifically to the "natural system" of the 2.5m telescope defined by the photon-weighted effective wavelengths of each combination of SDSS filter, CCD response, telescope transmission, and atmospheric transmission at a reference airmass of 1.3 as measured at APO.
The calibration process ultimately involves combining data from three
telescopes: the USNO 40-in on which our primary
standards were first measured, the
SDSS Photometric Telescope (or PT) , and the SDSS 2.5m telescope.
At the beginning of the survey it was expected that there would be a
single u'g'r'i'z' system. However, in the course of processing the
SDSS data, the unpleasant discovery was made that the filters in the
2.5m telescope have significantly different effective wavelengths from
the filters in the PT and at the USNO. These differences have been
traced to the fact that the short-pass interference films on the
2.5-meter camera live in the same vacuum as the detectors, and the
resulting dehydration of the films decreases their effective
refractive index. This results in blueward shifts of the red edges of
the filters by about 2.5 percent of the cutoff
wavelength, and consequent shifts of the effective
wavelengths of order half that. The USNO filters are in ambient air,
and the hydration of the films exhibits small temperature shifts; the
PT filters are kept in stable very dry air and are in a condition
about halfway between ambient and the very stable vacuum state. The
rather subtle differences between these systems are describable by
simple linear transformations with small color terms for stars of
not-too-extreme color, but of course cannot be so transformed for very
cool objects or objects with complex spectra. Since standardization is
done with stars, this is not a fundamental problem, once the
transformations are well understood.
were first measured, the
SDSS Photometric Telescope (or PT) , and the SDSS 2.5m telescope.
At the beginning of the survey it was expected that there would be a
single u'g'r'i'z' system. However, in the course of processing the
SDSS data, the unpleasant discovery was made that the filters in the
2.5m telescope have significantly different effective wavelengths from
the filters in the PT and at the USNO. These differences have been
traced to the fact that the short-pass interference films on the
2.5-meter camera live in the same vacuum as the detectors, and the
resulting dehydration of the films decreases their effective
refractive index. This results in blueward shifts of the red edges of
the filters by about 2.5 percent of the cutoff
wavelength, and consequent shifts of the effective
wavelengths of order half that. The USNO filters are in ambient air,
and the hydration of the films exhibits small temperature shifts; the
PT filters are kept in stable very dry air and are in a condition
about halfway between ambient and the very stable vacuum state. The
rather subtle differences between these systems are describable by
simple linear transformations with small color terms for stars of
not-too-extreme color, but of course cannot be so transformed for very
cool objects or objects with complex spectra. Since standardization is
done with stars, this is not a fundamental problem, once the
transformations are well understood.
It is these subtle issues that gave rise to our somewhat awkward nomenclature for the different magnitude systems:
Previous reductions of the data, including that used in the EDR, were based on inconsistent photometric equations; this is why we referred to the 2.5m photometry with asterisks: u*g*r*i*z*. With the DR1, the photometric equations are properly self-consistent, and we can now remove the stars, and refer to u g r i z photometry with the 2.5m.
The photometric calibration of the SDSS imaging data is a multi-step process, due to the fact that the images from the 2.5m telescope saturate at approximately r = 14, fainter than typical spectrophotometric standards, combined with the fact that observing efficiency would be greatly impacted if the 2.5m needed to interrupt its routine scanning in order to observe separate calibration fields.
The first step involved setting up a primary standard star network of 158 stars distributed around the Northern sky. These stars were selected from a variety of sources and span a range in color, airmass, and right ascension. They were observed repeatedly over a period of two years using the US Naval Observatory 40-in telescope located in Flagstaff, Arizona. These observations are tied to an absolute flux system by the single F0 subdwarf star BD+17_4708, whose absolute fluxes in SDSS filters are taken from Fukugita et al. 1996 As noted above, the photometric system defined by these stars is called the u'g'r'i'z' system. You can look at the table containing the calibrated magnitudes for these standard stars.
Most of these primary standards have brightnesses in the range r = 8 - 13, and would saturate the 2.5-meter telescope's imaging camera in normal operations. Therefore, a set of 1520 41.5x41.5 arcmin2 transfer fields, called secondary patches, have been positioned throughout the survey area. These secondary patches are observed with the PT; their size is set by the field of view of the PT camera. These secondary patches are grouped into sets of four. Each set spans the full set of 12 scan lines of a survey stripe along the width of the stripe, and the sets are spaced along the length of a stripe at roughly 15 degree intervals. The patches are observed by the PT in parallel with observations of the primary standards and processed using the Monitor Telescope Pipeline (mtpipe). The patches are first calibrated to the USNO 40-in u'g'r'i'z' system and then transformed to the 2.5m ugriz system; both initial calibration to the u'g'r'i'z' system and the transformation to the ugriz system occur within mtpipe. The ugriz-calibrated patches are then used to calibrate the 2.5-meter's imaging data via the Final Calibrations Pipeline (nfcalib).
The PT has two main functions: it measures the atmospheric extinction on each clear night based on observations of primary standards at a variety of airmasses, and it calibrates secondary patches in order to determine the photometric zeropoint of the 2.5m imaging scans. The extinction must be measured on each night the 2.5m is scanning, but the corresponding secondary patches can be observed on any photometric night, and need not be coincident with the image scans that they will calibrate.
The Monitor Telescope Pipeline (mtpipe), so called for historical reasons, processes the PT data. It performs three basic functions:
The final calibration pipeline (nfcalib) works much like mtpipe, computing the transformation between psf photometry (or other photometry) as observed by the 2.5m telescope and the final SDSS photometric system. The pipeline matches stars between a camera column of 2.5m data and an overlapping secondary patch. Each camera column of 2.5m data is calibrated individually. There are of order 100 stars in each patch in the appropriate color and magnitude range in the overlap.
The transformation equations are a simplified form of those used by mtpipe.
Since mtpipe delivers patch stars already calibrated to the
2.5m ugriz system, the nfcalib transformation equations have the following
form:
mfilter_inst(2.5m) = mfilter(patch) + afilter + kfilterX,
where, for a given filter, mfilter_inst(2.5m) is the
instrumental magnitude of the star in the 2.5m data [-2.5 log10(counts/exptime)],
mfilter(patch) is the magnitude of the same star in
the PT secondary patch, afilter is the photometric
zeropoint, kfilter is the first-order extinction
coefficient, and X is the airmass of the 2.5m observation. The
extinction coefficient is taken from PT observations on the same
night, linearly interpolated in time when multiple extinction
determinations are available. (Generally, however, mtpipe calculates
only a single kfilter per filter per night, so
linear interpolation is usually unnecessary.) A single zeropoint
afilter is computed for each filter from stars
on all patches that overlap a given CCD in a given run. Observations
are weighted by their estimated errors, and sigma-clipping is used to
reject outliers. At one time it was thought that a time dependent
zero point might be needed to account for the fact that the 2.5m
camera and corrector lenses rotate relative to the telescope mirrors
and optical structure; however, it now appears that any variations in
throughput are small compared to inherent fluctuations in the
calibration of the patches themselves. The statistical error in the
zeropoint is usually constrained to be less than 1.35 percent
in u and z and 0.9 percent in gri.
With Data Release 1 (DR1), we now routinely meet our requirements of photometric uniformity of 2% in r, g-r, and r-i and of 3% in u-g and i-z (rms).
This is a substantial improvement over the photometric uniformity achieved in the Early Data Release (EDR), where the corresponding values were approximately 5% in r, g-r, and r-i and 5% in u-g and i-z.
The improvements between the photometric calibration of the EDR and the DR1 can be traced primarily to the use of more robust and consistent photometric equations by mtpipe and nfcalib and to improvements to the PSF-fitting algorithm and flatfield methodology in the Photometric Pipeline (photo).
Note that this photometric uniformity is measured based upon
relatively bright stars which are no redder than M0; hence, these
measures do not include effects of the
u band red leak (see caveats below) or the
model magnitude bug.
All calibrated magnitudes in the photometric catalogs are
given not as conventional Pogson astronomical
magnitudes, but as asinh
magnitudes. We show how to obtain both kinds of magnitudes from
observed count rates and vice versa. See further down for conversion of SDSS magnitudes to physical fluxes.
For both kinds of magnitudes, there are two ways to obtain the
zeropoint information for the conversion.
Here you first need the following information from the tsField files:
aa = zeropointTo get a calibrated magnitude, you first need to determine the extinction-corrected ratio of the observed count rate to the zero-point count rate:
Then, calculate either the conventional ("Pogson") or the SDSS asinh magnitude from f/f0:
| Band | b | Zero-Flux Magnitude [m(f/f0 = 0)] | m(f/f0 = 10b) |
| u | 1.4 × 10-10 | 24.63 | 22.12 |
| g | 0.9 × 10-10 | 25.11 | 22.60 |
| r | 1.2 × 10-10 | 24.80 | 22.29 |
| i | 1.8 × 10-10 | 24.36 | 21.85 |
| z | 7.4 × 10-10 | 22.83 | 20.32 |
Note: These values of the softening parameter b are set to be approximately 1-sigma of the sky noise; thus, only low signal-to-noise ratio measurements are affected by the difference between asinh and Pogson magnitudes. The final column gives the asinh magnitude associated with an object for which f/f0 = 10b; the difference between Pogson and asinh magnitudes is less than 1% for objects brighter than this.
The calibrated asinh magnitudes are given in the tsObj files. To obtain counts from an asinh magnitude, you first need to work out f/f0 by inverting the asinh relation above. You can then determine the number of counts from f/f0 using the zero-point, extinction coefficient, airmass, and exposure time.
The equations above are exact for DR1. Strictly speaking, for EDR photometry, the corrected counts should include a color term cc*(color-color0)*(X-X0) (cf. equation 15 in section 4.5 in the EDR paper), but it turns out that generally, cc*(color-color0)*(X-X0) < 0.01 mag and the color term can be neglected. Hence the calibration looks identical for EDR and DR1.
The "flux20" keyword in the header of the corrected frames (fpC files) approximately gives the net number of counts for a 20th mag object. So instead of using the zeropoint and airmass correction term from the tsField file, you can determine the corrected zero-point flux as
Then proceed with the calculation of a magnitude from f/f0 as above.
The relation is only approximate because the final calibration information (provided by nfcalib) is not available at the time the corrected frames are generated. We expect the error here (compared to the final calibrated magnitude) to be of order 0.1 mag or so, as estimated from a couple of test cases we have tried out.
Note the counts measured by photo for each object are given in the fpObjc files, as e.g., "psfcounts", "petrocounts", etc.On a related note, in DR1 one can also use relations similar to the above to estimate the sky level in magnitudes per sq. arcsec (1 pixel = 0.396 arcsec). Either use the header keyword "sky" in the fpC files, or remember to first subtract "softbias" (= 1000) from the raw background counts in the fpC files. Note the sky level is also given in the tsField files. This note only applies to the DR1 and later data releases. Note also that the calibrated sky brightnesses reported in the tsField values have been corrected for atmospheric extinction.
The gain is reported in the headers of the tsField and fpAtlas files (and hence also in the field table in the CAS). The total noise contributed by dark current and read noise (in units of DN2) is also reported in the tsField files in header keyword dark_variance (and correspondingly as darkVariance in the field table in the CAS), and also as dark_var in the fpAtlas header.
Thus, the error in DN is given by the following expression:
where counts is the number of object counts, sky is the number of sky counts summed over the same area as the object counts, Npix is the area covered by the object in pixels, and gain and dark_variance are the numbers from the corresponding tsField files.
The SDSS photometry is intended to be on the AB system (Oke & Gunn 1983), by which a magnitude 0 object should have the same counts as a source of Fnu = 3631 Jy. However, this is known not to be exactly true, such that the photometric zeropoints are slightly off the AB standard. We continue to work to pin down these shifts. Our present estimate, based on comparison to the STIS standards of Bohlin, Dickinson, & Calzetti~(2001) and confirmed by SDSS photometry and spectroscopy of fainter hot white dwarfs, is that the u band zeropoint is in error by 0.04 mag, uAB = uSDSS - 0.04 mag, and that g, r, and i are close to AB. These statements are certainly not precise to better than 0.01 mag; in addition, they depend critically on the system response of the SDSS 2.5-meter, which was measured by Doi et al. (2004, in preparation). The z band zeropoint is not as certain at this time, but there is mild evidence that it may be shifted by about 0.02 mag in the sense zAB = zSDSS + 0.02 mag. The large shift in the u band was expected because the adopted magnitude of the SDSS standard BD+17 in Fukugita et al.(1996) was computed at zero airmass, thereby making the assumed u response bluer than that of the USNO system response.
We intend to give a fuller report on the SDSS zeropoints, with uncertainties, in the near future. Note that our relative photometry is quite a bit better than these numbers would imply; repeat observations show that our calibrations are better than 2%.
As explained in the preceding section, the SDSS system is nearly an AB system. Assuming you know the correction from SDSS zeropoints to AB zeropoints (see above), you can turn the AB magnitudes into a flux density using the AB zeropoint flux density. The AB system is defined such that every filter has a zero-point flux density of 3631 Jy (1 Jy = 1 Jansky = 10-26 W Hz-1 m-2 = 10-23 erg s-1 Hz-1 cm-2).
Then you need to apply the correction for the zeropoint offset between the SDSS system and the AB system. We do not know this correction yet, so the fluxes you obtain by assuming that SDSS = AB may be affected by a systematic shift of probably at most 10%.
The spectro1d pipeline performs a sequence of tasks for each object spectrum on a plate: The spectrum and error array are read in, along with the pixel mask. Pixels with mask bits set to FULLREJECT, NOSKY, NODATA, or BRIGHTSKY are given no weight in the spectro1d routines. The continuum is then fitted with a fifth-order polynomial, with iterative rejection of outliers (e.g., strong lines). The fit continuum is subtracted from the spectrum. The continuum-subtracted spectra are used for cross-correlating with the stellar templates.

 ) with translation and scale parameters a and
b. We apply the à trous wavelet (Starck,
Siebenmorgen, & Gredel 1997). For fixed wavelet scale b,
the wavelet transform is computed at each pixel center a; the
scale b is then increased in geometric steps and the process
repeated. Once the full wavelet transform is computed, the code finds
peaks above a threshold and eliminates multiple detections (at
different b) of a given line by searching nearby pixels. The
output of this routine is a set of positions of candidate emission
lines.
) with translation and scale parameters a and
b. We apply the à trous wavelet (Starck,
Siebenmorgen, & Gredel 1997). For fixed wavelet scale b,
the wavelet transform is computed at each pixel center a; the
scale b is then increased in geometric steps and the process
repeated. Once the full wavelet transform is computed, the code finds
peaks above a threshold and eliminates multiple detections (at
different b) of a given line by searching nearby pixels. The
output of this routine is a set of positions of candidate emission
lines. This list of lines with nonzero weights is matched against a list of common galaxy and quasar emission lines, many of which were measured from the composite quasar spectrum of Vanden Berk et al.(2001; because of velocity shifts of different lines in quasars, the wavelengths listed do not necessarily match their rest-frame values). Each significant peak found by the wavelet routine is assigned a trial line identification from the common list (e.g., MgII) and an associated trial redshift. The peak is fitted with a Gaussian, and the line center, width, and height above the continuum are stored in HDU 2 of the spSpec*.fits files as parameters wave, sigma, and height, respectively. If the code detects close neighboring lines, it fits them with multiple Gaussians. Depending on the trial line identification, the line width it tries to fit is physically constrained. The code then searches for the other expected common emission lines at the appropriate wavelengths for that trial redshift and computes a confidence level (CL) by summing over the weights of the found lines and dividing by the summed weights of the expected lines. The CL is penalized if the different line centers do not quite match. Once all of the trial line identifications and redshifts have been explored, an emission-line redshift is chosen as the one with the highest CL and stored as z in the EmissionRedshift table and the spSpec*.fits emission line HDU. The exact expression for the emission-line CL has been tweaked to match our empirical success rate in assigning correct emission-line redshifts, based on manual inspection of a large number of spectra from the EDR.
The SpecLine table also gives the errors, continuum, equivalent width, chi-squared, spectral index, and significance of each line. We caution that the emission-line measurement for Hα should only be used if chi-squared is less than 2.5. In the SpecLine table, the "found" lines in HDU1 denote only those lines used to measure the emission-line redshift, while "measured" lines in HDU2 are all lines in the emission-line list measured at the redshifted positions appropriate to the final redshift assigned to the object.
A separate routine searches for high-redshift (z > 2.3) quasars by identifying spectra that contain a Lyα forest signature: a broad emission line with more fluctuation on the blue side than on the red side of the line. The routine outputs the wavelength of the Lyα emission line; while this allows a determination of the redshift, it is not a high-precision estimate, because the Lyα line is intrinsically broad and affected by Lyα absorption. The spectro1d pipeline stores this as an additional emission-line redshift. This redshift information is stored in the EmissionRedshift table.
If the highest CL emission-line redshift uses lines only expected for quasars (e.g., Lyα, CIV, CIII], then the object is provisionally classified as a quasar. These provisional classifications will hold up if the final redshift assigned to the object (see below) agrees with its emission redshift.
The spectra are cross-correlated with stellar, emission-line galaxy, and quasar template spectra to determine a cross-correlation redshift and error. The cross-correlation templates are obtained from SDSS commissioning spectra of high signal-to-noise ratio and comprise roughly one for each stellar spectral type from B to almost L, a nonmagnetic and a magnetic white dwarf, an emission-line galaxy, a composite LRG spectrum, and a composite quasar spectrum (from Vanden Berk et al. 2001). The composites are based on co-additions of ∼ 2000 spectra each. The template redshifts are determined by cross-correlation with a large number of stellar spectra from SDSS observations of the M67 star cluster, whose radial velocity is precisely known.
When an object spectrum is cross-correlated with the stellar templates, its found emission lines are masked out, i.e., the redshift is derived from the absorption features. The cross-correlation routine follows the technique of Tonry & Davis (1979): the continuum-subtracted spectrum is Fourier-transformed and convolved with the transform of each template. For each template, the three highest cross-correlation function (CCF) peaks are found, fitted with parabolas, and output with their associated confidence limits. The corresponding redshift errors are given by the widths of the CCF peaks. The cross-correlation CLs are empirically calibrated as a function of peak level based on manual inspection of a large number of spectra from the EDR. The final cross-correlation redshift is then chosen as the one with the highest CL from among all of the templates.
If there are discrepant high-CL cross-correlation peaks, i.e., if the highest peak has CL < 0.99 and the next highest peak corresponds to a CL that is greater than 70% of the highest peak, then the code extends the cross-correlation analysis for the corresponding templates to lower wavenumber and includes the continuum in the analysis, i.e., it chooses the redshift based on which template provides a better match to the continuum shape of the object. These flagged spectra are then manually inspected (see below). The cross-correlation redshift is stored as z in the CrossCorrelationRedshift table.
The spectro1d pipeline assigns a final redshift to each object spectrum by choosing the emission or cross-correlation redshift with the highest CL and stores this as z in the SpecObj table. A redshift status bit mask zStatus and a redshift warning bit mask zWarning are stored. The CL is stored in zConf. Objects with redshifts determined manually (see below) have CL set to 0.95 (MANUAL_HIC set in zStatus), or 0.4 or 0.65 (MANUAL_LOC set in zStatus). Rarely, objects have the entire red or blue half of the spectrum missing; such objects have their CLs reduced by a factor of 2, so they are automatically flagged as having low confidence, and the mask bit Z_WARNING_NO_BLUE or Z_WARNING_NO_RED is set in zWarning as appropriate.
All objects are classified in specClass as either a quasar, high-redshift quasar, galaxy, star, late-type star, or unknown. If the object has been identified as a quasar by the emission-line routine, and if the emission-line redshift is chosen as the final redshift, then the object retains its quasar classification. Also, if the quasar cross-correlation template provides the final redshift for the object, then the object is classified as a quasar. If the object has a final redshift z > 2.3 (so that Lyα is or should be present in the spectrum), and if at least two out of three redshift estimators agree on this (the three estimators being the emission-line, Lyα, and cross-correlation redshifts), then it is classified as a high-z quasar. If the object has a redshift cz < 450 km s-1, then it is classified as a star. If the final redshift is obtained from one of the late-type stellar cross-correlation templates, it is classified as a late-type star. If the object has a cross-correlation CL < 0.25, it is classified as unknown.
There exist among the spectra a small number of composite objects. Most common are bright stars on top of galaxies, but there are also galaxy-galaxy pairs at distinct redshifts, and at least one galaxy-quasar pair, and one galaxy-star pair. Most of these have the zWarning flag set, indicating that more than one redshift was found.
The zWarning bit mask mentioned above records problems that the spectro1d pipeline found with each spectrum. It provides compact information about the spectra for end users, and it is also used to trigger manual inspection of a subset of spectra on every plate. Users should particularly heed warnings about parts of the spectrum missing, low signal-to-noise ratio in the spectrum, significant discrepancies between the various measures of the redshift, and especially low confidence in the redshift determination. In addition, redshifts for objects with zStatus = FAILED should not be used.
In addition to spectral classification based on measured lines,
galaxies are classified by a Principal Component Analysis (PCA), using
cross-correlation with eigentemplates constructed from SDSS
spectroscopic data. The 5 eigencoefficients and a classification
number are stored in eCoeff and eClass,
respectively, in the SpecObj table and the spSpec
files. eClass, a single-parameter classifier based on the
expansion coefficients (eCoeff1-5), ranges from about
-0.35 to 0.5 for early- to late-type galaxies.
A number of
changes to eClass have occurred since the EDR. The
galaxy spectral classification eigentemplates for DR1 are created from
a much larger sample of spectra than were used in the Stoughton et al. EDR
paper, and now number
approximately 200,000. The eigenspectra used in DR1 are an early
version of those created by Yip et al. (in prep). The sign of the
second eigenspectrum has been reversed with respect to that of EDR;
therefore we recommend using the expression
atan(-eCoeff2/eCoeff1)
rather than
eClass as the single-parameter classifier.
A small percentage of spectra on every plate are inspected manually, and if necessary, the redshift, classification, zStatus, and CL are corrected. We inspect those spectra that have zWarning or zStatus indicating that there were multiple high-confidence cross-correlation redshifts, that the redshift was high (z > 3.2 for a quasar or z > 0.5 for a galaxy), that the confidence was low, that signal-to-noise ratio was low in r, or that the spectrum was not measured. All objects with zStatus = EMLINE_HIC or EMLINE_LOC, i.e., for which the redshift was determined only by emission lines, are also examined. If, however, the object has a final CL > 0.98 and zStatus of either XCORR_EMLINE or EMLINE_XCORR, then despite the above, it is not manually checked. All objects with either specClass = SPEC_UNKNOWN or zStatus = FAILED are manually inspected.
Roughly 8% of the spectra in the EDR were thus inspected, of which about one-eighth, or 1% overall, had the classification, redshift, zStatus, or CL manually corrected. Such objects are flagged with zStatus changed to MANUAL_HIC or MANUAL_LOC, depending on whether we had high or low confidence in the classification and redshift from the manual inspection. Tests on the validation plates, described in the next section, indicate that this selection of spectrafor manual inspection successfully finds over 95% of the spectra for which the automated pipeline assigns an incorrect redshift.
In addition to reading this section, we recommend that users
familiarize themselves with the ,
which indicate what happened to each object during the Resolve
procedure.
SDSS scans overlap, leading to duplicate detections of objects in the overlap regions. A variety of unique (i.e., containing no duplicate detections of any objects) well-defined (i.e., areas with explicit boundaries) samples may be derived from the SDSS database. This section describes how to define those samples. The resolve figure is a useful visual aid for the discussion presented below.
Consider a single drift scan along a stripe, called a run. The camera has six columns of CCDs, which scan six swaths across the sky. A given camera column is referred to throughout with the abbreviation camCol. The unit for data processing is the data from a single camCol for a single run. The same data may be processed more than once; repeat processing of the same run/camCol is assigned a unique rerun number. Thus, the fundamental unit of data process is identified by run/rerun/camCol.
While the data from a single run/rerun/camCol is a scan line of data 2048 columns wide by a variable number of rows (approximately 133000 rows per hour of scanning), for purposes of data processing the data is split up into frames 2048 columns wide by 1361 rows long, resulting in approximately 100 frames per scan line per hour of scanning. Additionally, the first 128 rows from the next frame is added to the previous frame, leading to frames 2048 columns wide by 1489 rows long, where the first and last 128 rows overlap the previous and next frame, respectively. Each frame is processed separately. This leads to duplicate detections for objects in the overlap regions between frames. For each frame, we split the overlap regions in half, and consider only those objects whose centroids lie between rows 64 and 1361+64 as the unique detection of that object for that run/rerun/camCol. These objects have the OK_RUN bit set in the "status" bit mask. Thus, if you want a unique sample of all objects detected in a given run/rerun/camCol, restrict yourself to all objects in that run/rerun/camCol with the OK_RUN bit set. The boundaries of this sample are poorly defined, as the area of sky covered depends on the telescope tracking. Objects must satisfy other criteria as well to be labeled OK_RUN; an object must not be flagged BRIGHT (as there is a duplicate "regular" detection of the same object); and must not be a deblended parent (as the children are already included); thus it must not be flagged BLENDED unless the NODEBLEND flag is set. Such objects have their GOOD bit set.
For each stripe, 12 non-overlapping but contiguous scan lines are defined parallel to the stripe great circle (that is, they are bounded by two lines of constant great circle latitude). Each scan line is 0.20977 arcdegrees wide (in great circle latitude). Each run/camCol scans along one of these scan lines, completely covering the extent of the scan line in latitude, and overlapping the adjacent scan lines by approximately 1 arcmin. Six of these scan lines are covered when the "north" strip of the stripe is scanned, and the remaining six are covered by the "south" strip. The fundamental unit for defining an area of the sky considered as observed at sufficient quality is the segment. A segment consists of all OK_RUN objects for a given run/rerun/camCol contained within a rectangle defined by two lines of constant great circle longitude (the east and west boundaries) and two lines of constant great circle latitude (the north and south boundaries, being the same two lines of constant great circle latitude which define the scan line). Such objects have their OK_SCANLINE bit set in the status bit mask. A segment consists of a contiguous set of fields, but only portions of the first and/or last field may be contained within the segment, and indeed a given field could be divided between two adjacent segments. If an object is in the first field in a segment, then its FIRST_FIELD bit is set, along with the OK_SCANLINE bit; if its not in the first field in the segment, then the OK_SCANLINE bit is set but the FIRST_FIELD bit is not set. This extra complication is necessary for fields which are split between two segments; those OK_SCANLINE objects without the FIRST_FIELD bit set would belong to the first segment (the segment for which this field is the last field in the segment), and those OK_SCANLINE objects with the FIRST_FIELD bit set would belong the the second segment (the segment for which this field is the first field in the segment).
A chunk consists of a non-overlapping contiguous set of segments which span a range in great circle longitude over all 12 scan lines for a single stripe. Thus, the set of OK_SCANLINE (with appropriate attention to the FIRST_FIELD bit) objects in all segments for a given chunk comprises a unique sample of objects in an area bounded by two lines of constant great circle longitude (the east and west boundaries of the chunk) and two lines of constant great circle latitude (+- 1.25865 degrees, the north and south boundaries of the chunk).
Segments and chunks are defined in great circle coordinates along their given stripe, and contain unique detections only when limited to other segments and chunks along the same stripe. Each stripe is defined by a great circle, which is a line of constant latitude in survey coordinates (in survey coordinates, lines of constant latitude are great circles while lines of constant longitude are small circles, switched from the usual meaning of latitude and longitude). Since chunks are 2.51729 arcdegrees wide, but stripes are separated by 2.5 degrees (in survey latitude), chunks on adjacent stripes can overlap (and towards the poles of the survey coordinate system chunks from more than two stripes can overlap in the same area of sky). A unique sample of objects spanning multiple stripes may then be defined by applying additional cuts in survey coordinates. For a given chunk, all objects that lie within +- 1.25 degrees in survey latitude of its stripe's great circle have the OK_STRIPE bit set in the "status" bit mask. All OK_STRIPE objects comprise a unique sample of objects across all chunks, and thus across the entire survey area. The southern stripes (stripes 76, 82, and 86) do not have adjacent stripes, and thus no cut in survey latitude is required; for the southern stripes only, all OK_SCANLINE objects are also marked as OK_STRIPE, with no additional survey latitude cuts.
Finally, the official survey area is defined by two lines of constant survey longitude for each stripe, with the lines being different for each stripe. All OK_STRIPE objects falling within the specified survey longitude boundaries for their stripe have the PRIMARY bit set in the "status" bit mask. Those objects comprise the unique SDSS sample of objects in that portion of the survey which has been finished to date. Those OK_RUN objects in a segment which fail either the great circle latitude cut for their segment, or the survey latitude or longitude cut for their stripe, have their SECONDARY bit set. They do not belong to the primary sample, and represent either duplicate detections of PRIMARY objects in the survey area, or detections outside the area of the survey which has been finished to date.
Objects that lie close to the bisector between frames, scan lines, or chunks present some difficulty. Errors in the centroids or astrometric calibrations can place such objects on either side of the bisector. A resolution is performed at all bisectors, and if two objects lie within 2 arcsec of each other, then one object is declared OK_RUN/OK_SCANLINE/OK_STRIPE (depending on the test), and the other is not.
There are two main strategies employed to avoid these difficulties:
the use of clipped means, and the use of rank statistics such as the
median.
Photo performs two levels of sky subtraction; when first processing
each frame it estimates a global sky level, and then, while searching
for and measuring faint objects, it re-estimates the sky level locally
(but not individually for every object).
The initial sky estimate is taken from the median value of every pixel
in the image (more precisely, every fourth pixel in the image),
clipped at 2.32634 sigma. This estimate of sky is corrected for the
bias introduced by using a median, and a clipped one at that. The
statistical
error in this value is then estimated from the values of sky determined
separately from the four quadrants of the image.
Using this initial sky estimation, Photo proceeds to find all the
bright objects (typically those with more than 60 sigma detections).
Among these are any saturated stars present on the frame, and Photo
is designed to remove the scattering wings from at least the brighter
of these --- this should include the scattering due to the
atmosphere, and also that due to scattering within the CCD membrane,
which is especially a problem in the i band. In fact, we have chosen
not to aggressively subtract the wings of stars, partly because
of the difficulty of handling the wings of stars that do not fall on
the frame, and partly due to our lack of a robust understanding of the
outer parts of the PSF . With the parameters
employed, only the very cores of the stars (out to 20 pixels) are ever
subtracted, and this has a negligible influence on the data. Information
about star-subtraction is recorded in the fpBIN files, in
HDU 4.
Once the BRIGHT detections have been processed, Photo
proceeds with a more local sky estimate. This is carried out by
finding the same clipped median, but now in 256x256 pixel
boxes, centered every 128 pixels. These values are again debiased.
This estimate of the sky is then subtracted from the data, using
linear interpolation between these values spaced 128 pixels apart; the
interpolation is done using a variant of the well-known Bresenham
algorithm usually employed to draw lines on
pixellated displays.
This sky image, sampled every 128x128 pixels is written out to
the fpBIN file in HDU 2; the estimated uncertainties in the sky
(as estimated from the interquartile range and converted to a standard
deviation taking due account of clipping) is stored in HDU 3. The
value of sky in each band and its error, as interpolated to the center
of the object, are written to the fpObjc files along with all
other measured quantities.
After all objects have been detected and removed, Photo has the option of re-determining the sky using the same 256x256 pixel boxes; in practice this has not proved to significantly affect the photometry.
Spectro1D fits spectral features at three separate stages during
the pipeline. The first two fits are fits to emission lines
only. They are done in the process of determining an emission line
redshift and these are referred to as foundLines. The
final fitting of the complete line list, i.e. both emission and
absorption lines, occurs after the object's classification has been
made and a redshift has been measured. These fits are known as
measuredLines. In all cases a single Gaussian is fitted
to a given feature, therefore the quality of the fit is only good
where this model holds up.
The first line fit is done when attempting to measure the object's emission line redshift. Wavelet filters are used to locate emission lines in the spectrum. The goal of these filters is to find strong emission features, which will be used as the basis for a more careful search. The lines identified by the wavelet filter are stored in the specLine table as foundLines, i.e., with the parameter category set to 1. They are stored without any identifications, i.e., they have restWave = 0.
Every one of these features is then tentatively matched to each of a list of candidate emission lines as given in the line table below, and a system of lines is searched for at the position indicated by the tentative matching. The best system of emission lines (if any) found in this process is used to calculate the object's emission-line redshift. The lines from this system and their parameters are stored in the specLine table as foundLines, i.e., with the parameter category set to 1. These lines are identified by their restWave as given in the line table below.
The final line fitting is done for all features (both emission and absorption) in the line list below, and occurs after the object has been classified and a redshift has been determined. This allows for a better continuum estimation and thus better line fits. This latter fit is stored in the specLine table with the parameter category set to 2.
| Type of fit | category | restWave |
|---|---|---|
| "Found" emission lines from wavelet filter | 1 | 0 |
| "Found" emission lines from best-fit system to wavelet detections | 1 | restWave from line list |
| "Measured" emission and absorption lines according to the object's classification and best redshift | 2 | restWave from line list |
For almost all purposes we recommend the use of the measuredLines (category=2) since these result from the most careful continuum measurement and precise line fits.
All of the line parameters are measured in the observed frame, and no correction has been made for the instrumental resolution.
The continuum is fit using a median/mean filter. A sliding window is created of length 300 pixels for galaxies and stars or 1000 pixels for quasars. Pixels closer than 8 pixels(560km/s) for galaxies and stars or 30 pixels (2100 km/s) for QSOs to any reference line are masked and not used in the continuum measurement. The remaining pixels in the filter are ordered and the values between the 40th and 60th percentile are averaged to give the continuum. The category=1 lines are fit with a cruder continuum which is given by a fifth order polynomial fit which iteratively rejects outlying points.
The list of lines which are fit are given as an HTML line table below. Note that many times a single line in the table actually represents multiple features. Since the line fits are allowed to drift in wavelength somewhat, the exact precision of the lines are not important. The wavelength precision does become important for the emission line determination. To improve the accuracy of the emission-line redshift determination for QSOs, the wavelength for many of the lines listed here are not the laboratory values, but the average values calculated from a sample of SDSS QSOs taken from Vanden Berk et al. 2001 AJ 122 .
Every line in the reference list is fit as a single Gaussian on top of the continuum subtracted spectrum. Lines that are deemed close enough are fitted simultaneously as a blend. The basic line fitting is performed by the SLATEC common mathematical library routine SNLS1E which is based on the Levenberg-Marquardt method. Parameters are constrained to fall within certain values by multiplying the returned chi-squared values by a steep function. Any lines with parameters falling close to these constraints should be treated with caution. The constraints are: sigma > 0.5 Angstrom, sigma < 100 Angstrom, and the center wavelength is allowed to drift by no more than 450 km/sec for stars and galaxies or 1500 km/sec for QSOs, except for the CIV line which is allowed to be shifted by as much as 3000 km/sec.
There are a number of ways that the line fitting can fail. If the continuum is bad the line fits will be compromised. The median/mean filtering routine will always fail for white dwarfs, some A stars as well as late-type stars. In addition is has trouble for galaxies with a strong 4000 Angstrom break. Likewise the line fitting will have trouble when the lines are not really Gaussian. The Levenberg-Marquardt routine can fall into local minima, which can happen when there is self-absorption in a QSO line or both a narrow and broad component for example. One should always check the chi-squared values to evaluate the quality of the fit.
| restWave | Line |
|---|---|
| 1857.40 | AlIII_1857 |
| 8500.36 | CaII_8500 |
| 8544.44 | CaII_8544 |
| 8664.52 | CaII_8665 |
| 1335.31 | CII_1335 |
| 2326.00 | CII_2326 |
| 1908.73 | CIII_1909 |
| 1549.48 | CIV_1549 |
| 4305.61 | G_4306 |
| 3969.59 | H_3970 |
| 6564.61 | Ha_6565 |
| 4862.68 | Hb_4863 |
| 4102.89 | Hd_4103 |
| 3971.19 | He_3971 |
| 3889.00 | HeI_3889 |
| 1640.40 | HeII_1640 |
| 4341.68 | Hg_4342 |
| 3798.98 | Hh_3799 |
| 3934.78 | K_3935 |
| 6707.89 | Li_6708 |
| 1215.67 | Lya_1215 |
| 5176.70 | Mg_5177 |
| 2799.12 | MgII_2799 |
| 5895.60 | Na_5896 |
| 2439.50 | NeIV_2439 |
| 3346.79 | NeV_3347 |
| 3426.85 | NeVI_3427 |
| 6529.03 | NI_6529 |
| 6549.86 | NII_6550 |
| 6585.27 | NII_6585 |
| 1240.81 | NV_1241 |
| 1305.53 | OI_1306 |
| 6302.05 | OI_6302 |
| 6365.54 | OI_6366 |
| 3727.09 | OII_3727 |
| 3729.88 | OII_3730 |
| 1665.85 | OIII_1666 |
| 4364.44 | OIII_4364 |
| 4932.60 | OIII_4933 |
| 4960.30 | OIII_4960 |
| 5008.24 | OIII_5008 |
| 1033.82 | OVI_1033 |
| 3836.47 | Oy_3836 |
| 4072.30 | SII_4072 |
| 6718.29 | SII_6718 |
| 6732.67 | SII_6733 |
| 1397.61 | SiIV_1398 |
| 1399.80 | SiIV_OIV_1400 |
and each TARGET
photo object points to a spectroscopic object if there is one nearby the photo
object (ra,dec).
Each SPECTRO object points to a BEST photo object if there is one nearby the spectro (ra,dec) and a TARGET object id if there is a nearby one.
We chose 1 arc seconds as the "nearby radius" since that approximates the fiber radius.
This is complicated by the fact that
, secondary
objects).
To resolve these ambiguities, we defined two views:
 is the subset of
PhotoObjAll that are the primary objects.
is the subset of
SpecObjAll that are the "science primary"
spectroscopic objects.
is the subset of
PhotoObjAll that are the primary objects.
is the subset of
SpecObjAll that are the "science primary"
spectroscopic objects.
There is at most one "primary" object at any spot in the sky.
So, the logic is as follows:
objects point to the
closest BEST photoObj object if there is one within 1 arcseconds.
TargetInfo.targetObjID is set while loading the data for a
chunk into TARGET. The only difference between a
targetID and targetObjID is the possible flip of one bit. This bit
distinguishes between identical PhotoObjAll objects that are in fields that
straddle 2 chunks. Only one of the pair will actually be within the chunk
boundaries, so we want to make sure we match to that one. Note that the one
of the pair that is actually part of a chunk might not be primary.
So, setting SpecObjAll.targetObjID does not use a positional match - it's all done through ID numbers. This match should always exist, so SpecObjAll.targetObjID always points to something in TARGET.PhotoObjAll. However, it is not guaranteed that SpecObjAll.targetObjID will match something in TARGET.PhotoObj because in the past we have targetted non-primaries (stripe 10 for example). To try to make this slightly less confusing we require something in SpecObj to have been targetted from something in TARGET.PhotoObj (ie primary spectra must have been primary targets).
SpecObjAll objects with targetObjID = 0 are usually fibers that were not mapped, so we didn't have any way to match them to the imaging (for either TARGET or BEST since we don't have an ID or position).
SpecObjAll.bestObjID is set as described above. To be slightly more detailed about the case where there is no BEST.PhotoObj within 1", we go through the modes (primary,secondary,family) in order looking for the nearest BEST.PhotoObjAll within 1".
BEST.PhotoObjAll.specObjID only points to things in SpecObj (ie SpecObjAll.sciencePrimary=1) because the mapping to non-sciencePrimary SpecObjAlls is not unique. You can still do BEST.PhotoObjAll.objID = SpecObjAll.bestObjID to get all the matches.
Ambiguities are not flagged. There are no ambiguities if you start from PhotoObj and go to SpecObj. It might be possible for more than one SpecObj to point to the same PhotoObj, but there are no examples of this unless it is a pathological case. It is possible for a SpecObj to point to something in PhotoObjAll that is not in PhotoObj, but if you are joining with PhotoObj you won't see these. If you start joining PhotoObjAll and SpecObjAll you need to be quite careful because the mapping is (necessarily) complicated.
Because the SDSS spectra are obtained through 3-arcsecond fibers during non-photometric observing conditions, special techniques must be employed to spectrophotometrically calibrate the data. There have been three substantial improvements to the algorithms which photometrically calibrate the spectra
On each spectroscopic plate, 16 objects are targeted as spectroscopic standards. These objects are color-selected to be F8 subdwarfs, similar in spectral type to the SDSS primary standard BD+17 4708.

The color selection of the SDSS standard stars. Red points represent stars selected as spectroscopic standards. (Most are flux standards; the very blue stars in the right hand plot are"hot standards"used for telluric absorption correction.)
The flux calibration of the spectra is handled
by the Spectro2d pipeline. It is performed separately for each of the 2
spectrographs, hence each half-plate has its own
calibration. In the EDR and DR1 Spectro2d calibration pipelines, fluxing was
achieved by assuming that the mean spectrum of the stars on each
half-plate was equivalent to a synthetic composite F8 subdwarf spectrum from
Pickles
(1998). In the reductions included in DR2, the spectrum of each standard
star is spectrally typed by comparing with a grid of theoretical spectra
generated from Kurucz model atmospheres (Kurucz
1992) using the spectral synthesis code SPECTRUM (Gray
& Corbally 1994; Gray,
Graham, & Hoyt 2001). The flux calibration vector is derived from the
average ratio of each star (after correcting for Galactic reddening) and its
best-fit model. Since the red and blue halves of the spectra are imaged onto
separate CCDs, separate red and blue flux calibration vectors are
produced. These will resemble the throughput curves under photometric
conditions. Finally, the red and blue halves of each spectrum on each exposure
are multiplied by the appropriate flux calibration vector. The spectra are
then combined with bad pixel rejection and rebinned to a constant
dispersion.
Throughput curves for the red and blue channels on the two SDSS spectrographs.
The EDR and DR1 data nominally corrected for galactic extinction. The spectrophotometry in DR2 is vastly improved compared to DR1, but the final calibrated DR2 spectra are not corrected for foreground Galactic reddening (a relatively small effect; the median E(B-V) over the survey is 0.034). This may be changed in future data releases. Users of spectra should note, though, that the fractional improvement in spectrophotometry is much greater than the extinction correction itself.
The second update in the pipeline is relatively minor: We now compute the absolute calibration by tying the r-band fluxes of the standard star spectra to the fiber magnitudes output by the latest version of the photometric pipeline. The latest version now corrects fiber magnitudes to a constant seeing of 2", and includes the contribution of flux from overlapping objects in the fiber aperture; these changes greatly improve the overall data consistency.
The third update to the spectroscopic pipeline is that we no longer use the "smear" observations in our calibration. As the EDR paper describes, "smear" observations are low signal-to-noise ratio (S/N) spectroscopic exposures made through an effective 5.5" by 9" aperture, aligned with the parallactic angle. Smears were designed to account for object light excluded from the 3" fiber due to seeing, atmospheric refraction and object extent. However, extensive experiments comparing photometry and spectrophotometry calibrated with and without smear observations have shown that the smear correction provides improvements only for point sources (stars and quasars) with very high S/N. For extended sources (galaxies) the spectrum obtained in the 3" fiber aperture is calibrated to have the total flux and spectral shape of the light in the smear aperture. This is undesirable, for example, if the fiber samples the bulge of a galaxy, but the smear aperture includes much of its disk: For extended sources, the effect of the smears was to give a systematic offset between spectroscopic and fiber magnitudes of up to a magnitude; with the DR2 reductions, this trend is gone. Finally, smear exposures were not carried out for one reason or another for roughly 1/3 of the plates in DR2. For this reason, we do not apply the smear correction to the data in DR2.
To the extent that all point sources are centered in the fibers in the same way as are the standards, our flux calibration scheme corrects the spectra for losses due to atmospheric refraction without the use of smears. Extended sources are likely to be slightly over-corrected for atmospheric refraction. However, most galaxies are quite centrally concentrated and more closely resemble point sources than uniform extended sources. In the mean, this overcorrection makes the g-r color of the galaxy spectra too red by ~1%.
Detailed descriptions of the selection algorithms for the different categories of SDSS targets are provided in the series of papers noted below under Target Selection References. Here we provide short summaries of the various target selection algorithms.
In the SDSS imaging data output tsObj files, the
result of target selection for each object is recorded in the 32-bit
primTarget flag, as defined in
Table 27 of Stoughton et al. (2002). For details, see the Target Selection References
Note the following subtleties:
. The following samples are targeted:
The main galaxy sample target selection algorithm is detailed in Strauss et al. (2002) and is summarized in this schematic flowchart.
Galaxy targets are selected starting from objects which are detected
in the r band (i.e. those objects which are more than 5σ
above sky after smoothing with a PSF filter).
The photometry is corrected for Galactic extinction using the
reddening maps of
Schlegel, Finkbeiner, and Davis (1998).
Galaxies are separated from stars using the following cut on the difference between
the r-band
PSF
and
model
magnitudes:
rPSF - rmodel >= 0.3
Note that this cut is more conservative for galaxies than the
star-galaxy separation cut used by Photo.
Potential targets are then rejected if they have been flagged by Photo
as SATURATED, BRIGHT, or BLENDED
The
Petrosian
magnitude limit rP = 17.77 is then applied, which
results in a main galaxy sample surface density of about 90 per deg2.
A number of surface brightness cuts are then applied, based on
mu50, the mean surface brightness within the Petrosian half-light
radius petroR50. The most significant cut is mu50
<= 23.0 mag arcsec-2 in r, which already
includes 99% of the galaxies brighter than the Petrosian magnitude
limit. At surface brightnesses in the range 23.0 <=
mu50 <= 24.5 mag arcsec-2, several other
criteria are applied in order to reject most spurious targets, as
shown in the flowchart. Please see the
detailed discussion of these surface brightness cuts, including
consideration of selection effects, in
Section 4.4 of Strauss et al. (2002). Finally, in order to reject
very bright objects which will cause contamination of the spectra of
adjacent fibers and/or saturation of the spectroscopic CCDs, objects
are rejected if they have (1)fiber magnitudes
brighter than 15.0 in g or r, or 14.5 in i;
or (2) Petrosian magnitude rP < 15.0 and Petrosian
half-light radius petroR50 < 2 arcsec.
Main galaxy targets satisfying all of the above criteria have the GALAXY bit set in their primTarget flag. Among those, the ones with mu50 >= 23.0 mag arcsec-2 have the GALAXY_BIG bit set. Galaxy targets who fail all the surface brightness selection limits but have r band fiber magnitudes brighter than 19 are accepted anyway (since they are likely to yield a good spectrum) and have the GALAXY_BRIGHT_CORE bit set.
SDSS luminous red galaxies (LRGs) are selected on the basis of color and magnitude to yield a sample of luminous intrinsically red galaxies that extends fainter and farther than the SDSS main galaxy sample. Please see Eisenstein et al. (2001) for detailed discussions of sample selection, efficiency, use, and caveats.
LRGs are selected using a variant of the photometric redshift technique
and are meant to comprise a uniform, approximately volume-limited sample of
objects with the reddest colors in the rest frame. The sample is
selected via cuts in the (g-r, r-i, r)
color-color-magnitude cube. Note that all colors are measured using
model magnitudes, and all quantities are
corrected for Galactic extinction following
Schlegel, Finkbeiner, and Davis (1998).
Objects must be detected by Photo as BINNED1, BINNED2, OR BINNED4
in both r and i, but not necessarily in g,
and objects flagged by Photo as BRIGHT or SATURATED in g, r,
or i are excluded.
The galaxy model colors are rotated first to a basis that is aligned with the galaxy locus in the (g-r, r-i) plane according to:
c&perp = (r-i) + (g-r)/4 + 0.18
c|| = 0.7(g-r) + 1.2[(r-i) - 0.18]
Because the 4000 Angstrom break moves from the g band to the r band at a redshift z ~ 0.4, two separate sets of selection criteria are needed to target LRGs below and above that redshift:
Cut I for z <~ 0.4
Cut II for z >~ 0.4
Cut I selection results in an approximately volume-limited LRG sample to z=0.38, with additional galaxies to z ~ 0.45. Cut II selection adds yet more luminous red galaxies to z ~ 0.55. The two cuts together result in about 12 LRG targets per deg2 that are not already in the main galaxy sample (about 10 in Cut I, 2 in Cut II).
In primTarget, GALAXY_RED is set if the LRG passes either Cut I or Cut II. GALAXY_RED_II is set if the object passes Cut II but not Cut I. However, neither of these flags is set if the LRG is brighter than the main galaxy sample flux limit but failed to enter the main sample (e.g., because of the main sample surface brightness cuts). Thus LRG target selection never overrules main sample target selection on bright objects.
The final adopted SDSS quasar target selection algorithm is described in Richards et al. (2002). However, it should be noted that the implementation of this algorithm came after the last date of DR1 spectroscopy. Thus this paper does not technically describe the DR1 quasar sample and the DR1 quasar sample is not intended to be used for statistical purposes (but see below). Interested parties are instead encouraged to use the catalog of DR1 quasars that is being prepared by Schneider et al (2003, in prep.), which will include an indication of which quasars were also selected by the Richards et al. (2002) algorithm. At some later time, we will also perform an analysis of those objects selected by the new algorithm but for which we do not currently have spectroscopy and will produce a new sample that is suitable for statistical analysis.
Though the DR1 quasars were not technically selected with the Richards et al. (2002) algorithm, the algorithms used since the EDR are quite similar to this algorithm and this paper suffices to describe the general considerations that were made in selecting quasars. Thus it is worth describing the algorithm in more detail.
The quasar target selection algorithms are summarized in this schematic flowchart. Because the quasar selection cuts are fairly numerous and detailed, the reader is strongly recommended to refer to Richards et al. (2002) (link to AJ paper; subscription required) for the full discussion of the sample selection criteria, completeness, target efficiency, and caveats.
The quasar target selection algorithm primarily identifies quasars as outliers from the stellar locus, modeled following Newberg & Yanny (1997) as elongated tubes in the (u-g, g-r, r-i) (denoted ugri) and (g-r, r-i, i-z) (denoted griz) color cubes. In addition, targets are also selected by matches to the FIRST catalog of radio sources (Becker, White, & Helfand 1995). All magnitudes and colors are measured using PSF magnitudes, and all quantities are corrected for Galactic extinction following Schlegel, Finkbeiner, and Davis (1998).
Objects flagged by Photo as having either "fatal" errors (primarily those
flagged BRIGHT, SATURATED, EDGE, or BLENDED;
or "nonfatal" errors
(primarily related to deblending or interpolation problems) are rejected
from the color selection, but only objects with fatal errors are rejected
from the FIRST radio selection. See
Section 3.2 of Richards et al. (2002) for the full details.
Objects are also rejected (from the color selection, but not the radio selection)
if they lie in any of 3 color-defined exclusion regions which are dominated
by white dwarfs, A stars, and M star+white dwarf pairs; see
Section 3.5.1 of Richards et al. (2002) for the specific exclusion region color boundaries.
Such objects are flagged as QSO_REJECT. Quasar targets are further restricted to
objects with iPSF > 15.0 in order to exclude bright objects
which will cause contamination of the spectra from adjacent fibers.
Objects which pass the above tests are then selected to be quasar targets if they lie more than 4σ from either the ugri or griz stellar locus. The detailed specification of the stellar loci and of the outlier rejection algorithm are provided in Appendices A and B of Richards et al. (2002). These color-selected quasar targets are divided into main (or low-redshift) and high-redshift samples, as follows:
These are outliers from the ugri stellar locus and are selected in the magnitude range 15.0 < iPSF < 19.1. Both point sources and extended objects are included, except that extended objects must have colors that are far from the colors of the main galaxy distribution and that are consistent with the colors of AGNs; these additional color cuts for extended objects are specified in Section 3.4.4 of Richards et al. (2002).
Even if an object is not a ugri stellar locus outlier, it may be selected as a main quasar sample target if it lies in either of these 2 "inclusion" regions: (1) "mid-z", used to select 2.5 < z < 3 quasars whose colors cross the stellar locus in SDSS color space; and (2) "UVX", used to duplicate selection of z <= 2.2 UV-excess quasars in previous surveys. These inclusion boxes are specified in Section 3.5.2 of Richards et al. (2002).
Note that the QSO_CAP and QSO_SKIRT distinction is kept for historical reasons (as some data that are already public use this notation) and results from an original intent to use separate selection criteria in regions of low ("cap") and high ("skirt") stellar density. It turns out that the selection efficiency is indistinguishable in the cap and skirt regions, so that the target selection used is in fact identical in the 2 regions (similarly for QSO_FIRST_CAP and QSO_FIRST_SKIRT, below).
These are outliers from the griz stellar locus and are selected in the magnitude range 15.0 < iPSF < 20.2. Only point sources are selected, as these quasars will lie at redshifts above z~3.5 and are expected to be classified as stellar at SDSS resolution. Also, to avoid contamination from faint low-redshift quasars which are also griz stellar locus outliers, blue objects are rejected according to eq. (1) in Section 3.4.5 of Richards et al. (2002).
Moreover, several additional color cuts are used in order to recover more high-redshift quasars than would be possible using only griz stellar locus outliers. So an object will be selected as a high-redshift quasar target if it lies in any of these 3 "inclusion" regions: (1) "gri high-z", for z >= 3.6 quasars; (2) "riz high-z", for z >= 4.5 quasars; and (3) "ugr red outlier", for z >= 3.0 quasars. The specifics are given in eqs. (6-8) in Section 3.5.2 of Richards et al. (2002).
Irrespective of the various color selection criteria above, SDSS stellar objects are selected as quasar targets if they have 15.0 < iPSF < 19.1 and are matched to within 2 arcsec of a counterpart in the FIRST radio catalog.
Finally, those targets which otherwise meet the color selection or radio selection criteria described above, but fail the cuts on iPSF, will be flagged as QSO_MAG_OUTLIER (also called QSO_FAINT). Such objects may be of interest for follow-up studies, but are not otherwise targeted for spectroscopy under routine operations (unless another "good" quasar target flag is set).
A variety of other science targets are also selected; see also
Section 4.8.4 of Stoughton et al. (2002). With the exception of
brown dwarfs, these samples are not complete, but are
assigned to excess fibers left over after the main samples of
galaxies, LRGs, and quasars have been tiled.
A variety of stars are also targeted using color selection criteria, as follows:
SDSS objects are positionally matched against X-ray sources from the ROSAT All-Sky Survey (RASS; Voges et al. 1999), and SDSS objects within the RASS error circles (commonly 10-20 arcsec) are targeted using algorithms tuned to select likely optical counterparts to the X-ray sources. Objects are targeted which:
Objects are flagged ROSAT_E if they fall within the RASS error circle but are either too faint or too bright for SDSS spectroscopy.
This is an open category of targets whose selection criteria may change as different regions of parameter space are explored. These consist of:
Tiling is the process by which the spectroscopic plates are designed
and placed relative to each other. This procedure involves optimizing
both the placement of fibers on individual
plates, as well as the placement of plates (or tiles) relative to each
other.
Much of the content of this page can be found as a
preprint on astro-ph.
NOTE: the term "chunk" or "tiling chunk" is sometimes
used to denote a tiling region. To avoid confusion with the
correct use of the term chunk, we use "tiling region" here.
 |  |
Figure 1: Simplified Tiling and Network Flow View | |
The basic idea is shown in the right half of Figure 1, which shows the appropriate network for the situation in the left half. Using this figure as reference, we here define some terms which are standard in combinatorial literature and which will be useful here:
Imagine a flow of 7 objects entering the network at
the source node at the left. We want the entire flow to leave
the network at the sink node at the right for the lowest possible
cost. The objects travel along the arcs, from node to node. Each
arc has a maximum capacity of objects which it can transport, as
labeled. (One can also specify a
As described above, there is a limit of 55" to how close two fibers can be on the same tile. If there were no overlaps between tiles, these collisions would make it impossible to observe ~10% of the SDSS targets. Because the tiles are circular, some fraction of the sky will be covered with overlaps of tiles, allowing some of these targets to be recovered. In the presence of these collisions, the best assignment of targets to the tiles must account for the presence of collisions, and strive to resolve as many as possible of these collisions which are in overlaps of tiles. We approach this problem in two steps, for reasons described below. First, we apply the network flow algorithm of the above section to the set of "decollided" targets --- the largest possible subset of the targets which do not collide with each other. Second, we use the remaining fibers and a second network flow solution to optimally resolve collisions in overlap regions.
 |
Figure 2: Fiber Collisions |
The "decollided" set of targets is the maximal subset of targets which are all greater than 55" from each other. To clarify what we mean by this maximal set, consider Figure 2. Each circle represents a target; the circle diameter is 55", meaning that overlapping circles are targets which collide. The set of solid circles is the "decollided" set. Thus, in the triple collision at the top, it is best to keep the outside two rather than the middle one.
This determination is complicated slightly by the fact that some
targets are assigned higher priority than others. For example, as
explained in the Targeting section, QSOs are
given higher priority than
galaxies by the SDSS target selection algorithms. What we mean here by
"priority" is that a higher priority target is guaranteed never to
be eliminated from the sample due to a collision with a lower priority
object. Thus, our true criterion for determining whether one set of
assignments of fibers to targets in a group is more favorable than
another is that a greater number of the highest priority objects are
assigned fibers.
Once we have identified our set of decollided objects, we use the network flow solution to find the best possible assignment of fibers to that set of objects.
After allocating fibers to the set of decollided targets, there will usually be unallocated fibers, which we want to use to resolve fiber collisions in the overlaps. We can again express the problem of how best to perform the collision resolution as a network, although the problem is a bit more complicated in this case. In the case of binaries and triples, we design a network flow problem such that the network flow solution chooses the tile assignments optimally. In the case of higher multiplicity groups, our simple method for binaries and triples does not work and we instead resolve the fiber collisions in a random fashion; however, fewer than 1% of targets are in such groups, and the difference between the optimal choice of assignments and the random choices made for these groups is only a small fraction of that.
We refer the reader to the tiling algorithm paper for more details, including how the fiber collision network flow is designed and caveats about what aspects of the method may need to be changed under different circumstances.
Once one understands how to assign fibers given a set of tile centers, one can address the problem of how best to place those tile centers. Our method first distributes tiles uniformly across the sky and then uses a cost-minimization scheme to perturb the tiles to a more efficient solution.
In most cases, we set initial conditions by simply laying down a rectangle of tiles. To set the centers of the tiles along the long direction of the rectangle, we count the number of targets along the stripe covered by that tile. The first tile is put at the mean of the positions of target 0 and target N_t, where N_t is the number of fibers per tile (592 for the SDSS). The second tile is put at the mean between target N_t and 2N_t, and so on. The counting of targets along adjacent stripes is offset by about half a tile diameter in order to provide more complete covering.
The method is of perturbing this uniform distribution is iterative. First, one allocates targets to the tiles, but instead of limiting a target to the tiles within a tile radius, one allows a target to be assigned to further tiles, but with a certain cost which increases with distance (remember that the network flow accommodates the assignment of costs to arcs). One uses exactly the same fiber allocation procedure as above. What this does is to give each tile some information about the distribution of targets outside of it. Then, once one has assigned a set of targets to each tile, one changes each tile position to that which minimizes the cost of its set of targets. Then, with the new positions, one reruns the fiber allocation, perturbs the tiles again, and so on. This method is guaranteed to converge to a minimum (though not necessarily a global minimum), because the total cost must decrease at each step.
In practice, we also need to determine the appropriate number of tiles to use. Thus, using a standard binary search, we repeatedly run the cost-minimization to find the minimum number of tiles necessary to satisfy the SDSS requirements, namely that we assign fibers to 99% of the decollided targets.
In order to test how well this algorithm works, we have applied it both to simulated and real data. These results are discussed in the Tiling paper.
There are a few technical details which may be useful to mention in the context of SDSS data. Most importantly, we will describe which targets within the SDSS are "tiled" in the manner described here, and how such targets are prioritized. Second, we will discuss the method used by SDSS to deal with the fact that the imaging and spectroscopy are performed within the same five-year time period. Third, we will describe the tiling outputs which the SDSS tracks as the survey progresses. Throughout, we refer to the code which implements the algorithm described above as tiling.
Only some of the spectroscopic target types identified by the target
selection algorithms in the SDSS are "tiled." These types (and their
designations in the primary and secondary target bitmasks) are
described in the Targeting pages). They consist
of most types of QSOs, main sample galaxies,
LRGs, hot standard stars, and brown dwarfs. These are the types of
targets for which tiling is run and for which we are attempting to
create a well-defined sample. Once the code has guaranteed fibers to
all possible "tiled targets," remaining fibers are assigned to other
target types by a separate code.
All of these target types are treated equivalently, except that they assigned different "priorities," designated by an integer. As described above, the tiling code uses them to help decide fiber collisions. The sense is that a higher priority object will never lose a fiber in favor of a lower priority object. The priorities are assigned in a somewhat complicated way for reasons immaterial to tiling, but the essence is the following: the highest priority objects are brown dwarfs and hot standards, next come QSOs, and the lowest priority objects are galaxies and LRGs. QSOs have higher priority than galaxies because galaxies are higher density and have stronger angular clustering. Thus, allowing galaxies to bump QSOs would allow variations in galaxy density to imprint themselves into variations in the density of QSOs assigned to fibers, which we would like to avoid. For similar reasons, brown dwarfs and hot standard stars (which have extremely low densities on the sky) are given highest priority.
Each tile, as stated above, is 1.49 degrees in radius, and has the capacity to handle 592 tiled targets. No two such targets may be closer than 55" on the same tile.
The operation of the SDSS makes it impossible to tile the entire 10,000 square degrees simultaneously, because we want to be able to take spectroscopy during non-pristine nights, based on the imaging which has been performed up to that point. In practice, periodically a "tiling region" of data is processed, calibrated, has targets selected, and is passed to the tiling code. During the first year of the SDSS, about one tiling region per month has been created; as more and more imaging is taken and more tiles are created, we hope to decrease the frequency with which we need to make tiling regions, and to increase their size.
A tiling region is defined as a set of rectangles on the sky (defined in
survey
coordinates). All of these rectangles cover only sky which has
been imaged and processed. However, in the case of tiling, targets
may be missed near the edges of a tiling region because that area
was not covered by tiles. Thus, tiling is actually run on a somewhat larger area than a single tiling region, so the areas near the edges of adjacent
tiling regions are also included. This larger area is known as a
The first tiling region which is "supported" by the SDSS is denoted Tiling Region 4. The first tiling region for which the version of tiling described here was run is Tiling Region 7. Tiling regions earlier than Tiling Region 7 used a different (less efficient) method of handling fiber collisions. The earlier version also had a bug which artificially created gaps in the distribution of the fibers. The locations of the known gaps are given in the EDR paper for Tiling Region 4 as the overlaps between plates 270 and 271, plates 312 and 313, and plates 315 and 363 (also known as tiles 118 and 117, tiles 76 and 75, and tiles 73 and 74).
In order to interpret the spectroscopic sample, one needs to use the information about how targets were selected, how the tiles were placed, and how fibers were assigned to targets. We refer to the geometry defined by this information as the "tiling window" and describe how to use it in detail elsewhere. As we note below, for the purposes of data release users it is also important to understand what the photometric imaging window which is released (including, if desired, masks for image defects and bright stars) and which plates have been released.
The observed velocity dispersion sigma is the result of the superposition of many individual stellar spectra, each of which has been Doppler shifted because of the star's motion within the galaxy. Therefore, it can be determined by analyzing the integrated spectrum of the whole galaxy - the galaxy integrated spectrum will be similar to the spectrum of the stars which dominate the light of the galaxy, but with broader absorption lines due to the motions of the stars. The velocity dispersion is a fundamental parameter because it is an observable which better quantifies the potential well of a galaxy.
Estimating velocity dispersions for galaxies which have integrated spectra which are dominated by multiple components showing different stellar populations and different kinematics (e.g. bulge and disk components) is complex. Therefore, the SDSS estimates the velocity dispersion only for spheroidal systems whose spectra are dominated by the light of red giant stars. With this in mind, we have selected galaxies which satisfy the following criteria:
Because the aperture of an SDSS spectroscopic fiber (3 arcsec)
samples only the inner parts of nearby galaxies, and because the spectrum
of the bulge of a nearby late-type galaxy can resemble that of an
early-type galaxy, our selection includes spectra of bulges of nearby
late-type galaxies. Note that weak emission lines, such as
Halpha and/or O II, could still be present in the selected spectra.
A number of objective and accurate methods for making velocity dispersion measurements have been developed (Sargent et al. 1977; Tonry & Davis 1979; Franx, Illingworth & Heckman 1989; Bender 1990; Rix & White 1992). These methods are all based on a comparison between the spectrum of the galaxy whose velocity dispersion is to be determined, and a fiducial spectral template. This can either be the spectrum of an appropriate star, with spectral lines unresolved at the spectra resolution being used, or a combination of different stellar types, or a high S/N spectrum of a galaxy with known velocity dispersion.
Since different methods can give significantly different results, thereby introducing systematic biases especially for low S/N spectra, we decided to use two different techniques for measuring the velocity dispersion. Both methods find the minimum of
chi2 = sum { [G - B * S]2 }
where G is the galaxy, S the star and B is the gaussian broadening
function (* denotes a convolution).
chi2 = sum { [G~(k) - B~(k,sigma) S~(k)]2 /Vark2},
where G~, B~ and S~ are the Fourier Transforms of G, B and S,
respectively, and Vark2 = sigmaG~2 + sigmaS~2 B~(k,sigma).
(Note that in Fourier space, the convolution is a multiplication.) chi2 = sum { [G(n) - B(n,sigma) S(n)]2 /Varn2}.
Because the S/N of the SDSS spectra are relatively low, we assume that the
observed absorption line profiles in early-type galaxies are
Gaussian. It is well known that the two methods have their own particular biases, so we carried out numerical simulations to calibrate these biases. In our simulations, we chose a template stellar spectrum measured at high S/N, broadened it using a Gaussian with rms sigmainput, added Gaussian noise, and compared the input velocity dispersion with the measured output value. The first broadening allows us to test how well the methods work as a function of velocity dispersion, and the addition of noise allows us to test how well the methods work as a function of S/N. Our simulations show that the systematic errors on the velocity dispersion measurements appear to be smaller than ~ 3% but estimates of low velocity dispersions (sigma< 100 km s-1) are more biased (~ 5%).
The SDSS uses 32 K and G giant stars in M67 as stellar templates. The SDSS velocity dispersion estimates are obtained by fitting the restframe wavelength range 4000-7000 Å, and then averaging the estimates provided by the "Fourier-fitting" and "Direct-fitting" methods. The error on the final value of the velocity dispersion is determined by adding in quadrature the errors on the two estimates (i.e., the Fourier-fitting and Direct-fitting). The typical error is between delta(logsigma) ~ 0.02 dex and 0.06 dex, depending on the signal-to-noise of the spectra. The scatter computed from repeated observations is ~ 0.04 dex, consistent with the amplitude of the errors on the measurements.
Estimates of sigma are limited by the instrumental dispersion and resolution. The instrumental dispersion of the SDSS spectrograph is 69 km s-1 per pixel, and the resolution is ~ 90 km s-1. In addition, the instrumental dispersion may vary from pixel to pixel, and this can affect measurements of sigma. These variations are estimated for each fiber by using arc lamp spectra (up to 16 lines in the range 3800-6170 Å and 39 lines between 5780-9230 Å). A simple linear fit provides a good description of these variations. This is true for almost all fibers, and allows us to remove the bias such variations may introduce when estimating galaxy velocity dispersions.
The velocity dispersion measurements distributed with SDSS spectra use template spectra convolved to a maximum sigma of 420 km/s. Therefore, velocity dispersion sigma > 420 km/s are not reliable and must not be used.
We recommend the user to not use SDSS velocity dispersion measurements for:
Also note that the velocity dispersion measurements output by the
SDSS spectro-1D pipeline are not corrected to a standard relative
circular aperture.
(The SDSS spectra measure the light within a fixed aperture of radius
1.5 arcsec. Therefore, the estimated velocity dispersions of more
distant galaxies are affected by the motions of stars at larger
physical radii than for similar galaxies which are nearby. If the
velocity dispersions of early-type galaxies decrease with radius,
then the estimated velocity dispersions (using a fixed aperture) of
more distant galaxies will be systematically smaller than those of
similar galaxies nearby.)
 Figure 1 (left). A has a blue
boundary, B has the red boundary, both Regions of depth 1. Their intersection
is yellow, a Region of depth 2. The crescent shaded in blue and green are the
two Sectors of depth 1, and the yellow area is a Sector of depth 2. Nodes are
purple dots.
Figure 1 (left). A has a blue
boundary, B has the red boundary, both Regions of depth 1. Their intersection
is yellow, a Region of depth 2. The crescent shaded in blue and green are the
two Sectors of depth 1, and the yellow area is a Sector of depth 2. Nodes are
purple dots.
 Figure 2 (right). This schematic
figure shows how the tiles and tilling rectangles can intersect to form
Sectors. On the figure we have a layout that has sectors of various depths,
depth 1 is gray, depth 2 is light blue, depth 3 is yellow and depth 4 is
magenta. The sectors are also clipped by the boundary.
Figure 2 (right). This schematic
figure shows how the tiles and tilling rectangles can intersect to form
Sectors. On the figure we have a layout that has sectors of various depths,
depth 1 is gray, depth 2 is light blue, depth 3 is yellow and depth 4 is
magenta. The sectors are also clipped by the boundary.
Regions can be described in many ways but here are the two we use:
For each tile T in the Tiles table
Now simplify all the new wedges and discard the empty one
using the fHtmToNormalForm function
Along the way, maintain the #TileWedge table.
Add T to #Tile
Great, we have the wedges and they are added to the Region, and Convex table. The depth is kept in the stripe column.
Now to compute the sectors, we do more or less the same thing.
For each wedge, call fGetOverlappingRegions(wedge,'TIGEOM',0)


{kind=link}